Free Preparation Discussions
Snowflake ARA-R01 Exam
- Topic 1: Domain 1: 25-30% Create a Snowflake account and database strategy aligned with business needs. Develop an architecture that satisfies data security, privacy, compliance, and governance standards. Define Snowflake security principles and determine suitable scenarios for their application.
- Topic 2: Domain 2: Snowflake Architecture 25-30% Examine the advantages and constraints of different data models within Snowflake. Devise data sharing strategies tailored to specific usage scenarios. Develop architectural solutions that accommodate Development Lifecycles and workload needs. Describe the organization of objects within the Snowflake Object hierarchy and its implications on architecture. Identify suitable data recovery approaches in Snowflake and methods for data restoration.
- Topic 3: Domain 3: Data Engineering 20-25% Identify the optimal data loading or unloading method to fulfill business requirements. Examine the primary tools within Snowflake's ecosystem and their integration with the platform. Decide on the suitable data transformation approach to align with business objectives.
- Topic 4: Domain 4: Performance Optimization 20-25% Summarize performance tools, recommended practices, and their ideal application scenarios. Address performance challenges within current architectures and resolve them effectively through troubleshooting techniques.
Free Snowflake ARA-R01 Exam Actual Questions
The questions for ARA-R01 were last updated On Apr. 22, 2024
A company is following the Data Mesh principles, including domain separation, and chose one Snowflake account for its data platform.
An Architect created two data domains to produce two data products. The Architect needs a third data domain that will use both of the data products to create an aggregate data product. The read access to the data products will be granted through a separate role.
Based on the Data Mesh principles, how should the third domain be configured to create the aggregate product if it has been granted the two read roles?
In the scenario described, where a third data domain needs access to two existing data products in a Snowflake account structured according to Data Mesh principles, the best approach is to utilize Snowflake's Data Exchange functionality. Option D is correct as it facilitates the sharing and governance of data across different domains efficiently and securely. Data Exchange allows domains to publish and subscribe to live data products, enabling real-time data collaboration and access management in a governed manner. This approach is in line with Data Mesh principles, which advocate for decentralized data ownership and architecture, enhancing agility and scalability across the organization. Reference:
Snowflake Documentation on Data Exchange
Articles on Data Mesh Principles in Data Management
A table, EMP_ TBL has three records as shown:
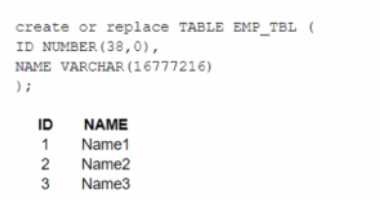
The following variables are set for the session:

Which SELECT statements will retrieve all three records? (Select TWO).
The correct answer is B and E because they use the correct syntax and values for the identifier function and the session variables.
The identifier function allows you to use a variable or expression as an identifier (such as a table name or column name) in a SQL statement. It takes a single argument and returns it as an identifier. For example, identifier($tbl_ref) returns EMP_TBL as an identifier.
The session variables are set using the SET command and can be referenced using the $ sign. For example, $var1 returns Name1 as a value.
Option A is incorrect because it uses Stbl_ref and Scol_ref, which are not valid session variables or identifiers. They should be $tbl_ref and $col_ref instead.
Option C is incorrect because it uses identifier<Stbl_ref>, which is not a valid syntax for the identifier function. It should be identifier($tbl_ref) instead.
Option D is incorrect because it uses Cvarl, var2, and var3, which are not valid session variables or values. They should be $var1, $var2, and $var3 instead.Reference:
Snowflake Documentation: Identifier Function
Snowflake Documentation: Session Variables
Snowflake Learning: SnowPro Advanced: Architect Exam Study Guide
Role A has the following permissions:
. USAGE on db1
. USAGE and CREATE VIEW on schemal in db1
. SELECT on tablel in schemal
Role B has the following permissions:
. USAGE on db2
. USAGE and CREATE VIEW on schema2 in db2
. SELECT on table2 in schema2
A user has Role A set as the primary role and Role B as a secondary role.
What command will fail for this user?
This command will fail because while the user has USAGE permission on db2 and schema2 through Role B, and can create a view in schema2, they do not have SELECT permission on db1.schemal.table1 with Role B. Since Role A, which has SELECT permission on db1.schemal.table1, is not the currently active role when the view v2 is being created in db2.schema2, the user does not have the necessary permissions to read from db1.schemal.table1 to create the view. Snowflake's security model requires that the active role have all necessary permissions to execute the command.
What actions are permitted when using the Snowflake SQL REST API? (Select TWO).
A. The Snowflake SQL REST API does support the use of a GET command, which can be used to retrieve the status of a previously submitted query or to fetch the results of a query once it has been executed. D. The use of a CALL command to a stored procedure is supported, which can return a result set, including a table. This allows the invocation of stored procedures within Snowflake through the SQL REST API.
What is the MOST efficient way to design an environment where data retention is not considered critical, and customization needs are to be kept to a minimum?
Transient databases in Snowflake are designed for situations where data retention is not critical, and they do not have the fail-safe period that regular databases have. This means that data in a transient database is not recoverable after the Time Travel retention period. Using a transient database is efficient because it minimizes storage costs while still providing most functionalities of a standard database without the overhead of data protection features that are not needed when data retention is not a concern.
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Currently there are no comments in this discussion, be the first to comment!